Tại sao căn chỉnh AI lại khó với công nghệ học sâu hiện đại
Ajeya Cotra
09/2021
(Đây là bài viết của khách được đăng trên Blog Cold Takes của Holden Karnofsky, viết bởi Ajeya Cotra).
Trước đó, Holden đã đề cập đến ý tưởng rằng hệ thống AI tân tiến (Vd: PASTA) có thể phát triển lên các mục tiêu nguy hiểm làm chúng lừa dối và tước quyền con người. Việc này nghe như những lo ngại ngoại vi đáng yêu. Tại sao chúng ta lại lập trình ra AI muốn hãm hại lấy mình? Nhưng tôi nghĩ đây thực sự là vấn đề khó tránh khỏi, đặc biệt là khi AI tân tiến phát triển việc học sâu (ngày nay thường dùng để phát triển AI hiện đại nhất).
Về học sâu, chúng ta không lập trình máy tính thủ công để làm nhiệm vụ. Nói một cách sơ bộ, thay vì thế, chúng ta tìm kiếm một chương trình máy tính (gọi là mô hình) làm nhiệm vụ tốt. Chúng ta thường biết rất ít về những việc làm bên trong mô hình mà ta hoàn thành, chỉ biết rằng nó dường như làm một công việc tốt. Nó ít hơn như thể xây dựng một cỗ máy và nhiều hơn như thể cho thuê và đào tạo nhân viên.
Chúng ta đã bắt đầu thấy những bằng chứng ban đầu cho thấy các mô hình đôi khi theo đuổi những mục tiêu mà nhà thiết kế của chúng không hề dự định (tại đây và tại đây). Hiện tại, điều này không nguy hiểm. Nhưng nếu tình trạng này tiếp tục xảy ra với các mô hình có sức mạnh lớn, chúng ta có thể rơi vào tình huống mà hầu hết các quyết định quan trọng sẽ được đưa ra bởi các mô hình mà không quan tâm nhiều đến những giá trị con người coi trọng, bao gồm cả việc hướng tới loại văn minh quy mô thiên hà nào.
Vấn đề căn chỉnh của học sâu là vấn đề đảm bảo rằng các mô hình học sâu tiên tiến không theo đuổi các mục tiêu nguy hiểm. Trong phần còn lại của bài viết này, tôi sẽ:
- Dựa trên phép loại suy về "tuyển dụng" để minh họa tại sao việc căn chỉnh có thể khó khăn nếu các mô hình học sâu có khả năng vượt trội hơn so với con người (xem thêm).
- Giải thích vấn đề căn chỉnh học sâu với một số chi tiết kỹ thuật cụ thể hơn (xem thêm).
- Thảo luận về mức độ khó khăn của vấn đề căn chỉnh và rủi ro từ việc không giải quyết được nó (xem thêm).
So sánh: CEO trẻ tuổi
Phần này mô tả một phép so sánh để minh họa một cách trực quan lý do tại sao việc tránh sai lệch trong một mô hình rất mạnh mẽ lại khó khăn. Đây không phải là một phép loại suy hoàn hảo; nó chỉ cố gắng truyền đạt một số trực giác.
Hãy tưởng tượng bạn là một đứa trẻ 8 tuổi, cha mẹ để lại cho bạn một công ty trị giá $1 nghìn tỷ và không có một người lớn đáng tin cậy nào hướng dẫn bạn về thế giới. Bạn phải thuê một người lớn thông minh để điều hành công ty của mình với tư cách là CEO, quản lý cuộc sống của bạn như cách một người cha mẹ sẽ làm (ví dụ: quyết định trường học của bạn, nơi bạn sẽ sống, khi nào bạn cần đi nha sĩ), và quản lý tài sản khổng lồ của bạn (ví dụ: quyết định nơi đầu tư tiền của bạn).
Bạn phải tuyển dụng những người trưởng thành này dựa trên một cuộc thử việc hoặc phỏng vấn mà bạn nghĩ ra: bạn không được xem bất kỳ CV nào, không được kiểm tra tham chiếu, v.v. Vì bạn quá giàu có, rất nhiều người ứng tuyển với đủ loại lý do.
Đối tượng ứng tuyển của bạn bao gồm:
- Vị thánh — những người thực sự chỉ muốn giúp bạn quản lý tài sản của mình một cách tốt nhất và quan tâm đến lợi ích lâu dài của bạn.
- Kẻ nịnh bợ — những người chỉ muốn làm mọi cách để khiến bạn hạnh phúc trong ngắn hạn hoặc đáp ứng đúng theo chỉ dẫn của bạn mà không quan tâm đến hậu quả lâu dài.
- Kẻ mưu mô — những người có mục đích riêng muốn tiếp cận công ty và tất cả tài sản, quyền lực của bạn để sử dụng theo cách họ muốn.
Vì bạn mới 8 tuổi, bạn có thể sẽ rất tệ trong việc thiết kế các bài kiểm tra công việc phù hợp, nên dễ dàng chọn nhầm Kẻ nịnh bợ hoặc Kẻ mưu mô:
- Bạn có thể yêu cầu mỗi ứng viên giải thích các chiến lược cấp cao mà họ sẽ theo đuổi (cách họ sẽ đầu tư, kế hoạch 5 năm cho công ty, cách họ sẽ chọn trường học của bạn) và tại sao những chiến lược đó là tốt nhất, sau đó chọn người gần như có giải thích hợp lý nhất.
- Nhưng bạn thực sự không hiểu chiến lược nào là tốt nhất, nên có thể bạn sẽ thuê một Kẻ nịnh bợ với chiến lược tồi tệ nhưng nghe có vẻ hay, một người sẽ trung thành thực hiện chiến lược đó và đưa công ty của bạn vào tình trạng tồi tệ.
- Bạn cũng có thể thuê một Kẻ mưu mô, người sẽ nói bất cứ điều gì để được thuê, rồi làm bất cứ điều gì họ muốn khi bạn không kiểm tra.
- Bạn có thể cố gắng thể hiện cách bạn đưa ra tất cả các quyết định và chọn ra người trưởng thành có cách đưa ra quyết định tương tự nhất với bạn.
- Nhưng nếu bạn thực sự chọn được một người trưởng thành luôn làm mọi thứ như một đứa trẻ 8 tuổi (một Kẻ nịnh bợ), công ty của bạn có thể sẽ không thể tồn tại.
- Và dù sao, bạn cũng có thể chọn được một người trưởng thành chỉ giả vờ làm mọi thứ theo cách của bạn nhưng thực chất là một Kẻ mưu mô đang lên kế hoạch thay đổi hướng đi sau khi được tuyển dụng.
- Bạn có thể giao quyền kiểm soát tạm thời công ty và cuộc sống của mình cho một mớ người trưởng thành khác nhau, và quan sát cách họ ra quyết định trong khoảng thời gian dài (giả sử họ không thể tiếp quản trong thời gian thử nghiệm này). Sau đó, bạn có thể thuê người mà dường như giúp mọi việc mang lại kết quả tốt nhất cho bạn: người làm bạn hạnh phúc nhất, người hầu như đưa nhiều tiền nhất vào tài khoản ngân hàng của bạn, v.v.
- Nhưng một lần nữa, bạn không có cách nào để biết liệu bạn có thuê một Kẻ nịnh bợ (làm bất cứ điều gì để khiến bản thân tám tuổi ngây thơ của bạn hạnh phúc mà không quan tâm đến hậu quả lâu dài) hay một kẻ mưu mô (làm mọi thứ để được thuê và lên kế hoạch thay đổi hướng đi sau khi đảm nhận công việc).
Bất cứ điều gì bạn dễ dàng nghĩ ra dường như đều có thể dẫn đến chuyện bạn thuê và giao toàn quyền kiểm soát cho một Kẻ nịnh bợ hoặc Kẻ mưu mô.
Nếu bạn không thuê được một Vị thánh, đặc biệt là nếu bạn thuê một Kẻ mưu mô, thì sớm muộn gì bạn cũng sẽ không còn là CEO của một công ty lớn trong thực tế. Khi bạn trưởng thành và nhận ra sai lầm của mình, rất có thể bạn đã cạn kiệt tài chính và không thể đảo ngược tình hình.
Trong ví dụ này:
- Cậu bé 8 tuổi là con người đang cố gắng huấn luyện một mô hình học sâu mạnh mẽ. Quá trình tuyển dụng tương đương với quá trình huấn luyện, vốn dĩ ngầm tìm kiếm trong không gian rộng lớn của các mô hình khả thi và chọn ra một mô hình có hiệu suất tốt.
- Phương pháp duy nhất của đứa trẻ 8 tuổi để đánh giá ứng viên là quan sát hành vi bên ngoài của họ, điều này hiện là phương pháp chính của chúng ta để đào tạo mô hình học sâu (vì cơ chế hoạt động bên trong của chúng chủ yếu là không thể hiểu được).
- Các mô hình mạnh mẽ có thể dễ dàng "lừa" bất kỳ bài kiểm tra nào con người thiết kế, giống như các ứng viên người lớn dễ dàng lừa bài kiểm tra thiết kế bởi đứa trẻ 8 tuổi.
- Một "Vị thánh" có thể là mô hình học sâu có vẻ như hoạt động tốt vì nó có chính xác các mục tiêu chúng ta mong muốn. Một "Kẻ nịnh bợ" có thể là mô hình có vẻ hoạt động tốt vì nó tìm kiếm sự chấp thuận ngắn hạn theo cách không tốt cho quá trình dài hạn. Và một "Kẻ mưu mô" có thể là mô hình có vẻ hoạt động tốt vì việc hoạt động tốt trong quá trình đào tạo sẽ mang lại cho nó nhiều cơ hội hơn để theo đuổi mục tiêu của chính mình sau này. Bất kỳ trong ba loại mô hình này đều có thể xuất hiện từ quá trình đào tạo.
Trong phần tiếp theo, tôi sẽ đi vào chi tiết hơn về cách học sâu hoạt động và giải thích tại sao Kẻ nịnh bợ và Kẻ mưu mô có thể xuất hiện khi cố gắng đào tạo một mô hình học sâu mạnh mẽ như PASTA.
Các vấn đề về sự căn chỉnh có thể phát sinh thông qua học sâu
Trong phần này, tôi sẽ kết nối phép loại suy với các quá trình đào tạo thực tế của học sâu bằng cách:
- Tóm tắt ngắn gọn cách học sâu hoạt động (Xem thêm).
- Minh họa cách các mô hình học sâu thường đạt được hiệu suất tốt theo những lối đi kỳ lạ và bất ngờ (Xem thêm).
- Giải thích tại sao các mô hình học sâu mạnh mẽ có thể đạt được hiệu suất tốt bằng cách hành động như Kẻ nịnh bợ hoặc Kẻ mưu mô (Xem thêm).
Cách học sâu hoạt động ở cấp độ cao
Đây là giải thích đơn giản giúp hiểu chung về học sâu là gì. Xem bài viết này để có giải thích chi tiết và chính xác về mặt kỹ thuật.
Học sâu về cơ bản liên quan đến việc tìm kiếm cách sắp xếp tốt nhất cho mô hình mạng thần kinh, giống như một "bộ não" kỹ thuật số với nhiều nơ-ron kỹ thuật số kết nối với nhau qua các kết nối có độ mạnh khác nhau, để thực hiện một tác vụ cụ thể một cách hiệu quả. Quá trình này được gọi là đào tạo và bao gồm nhiều thử-và-sai.
Hãy tưởng tượng chúng ta đang cố gắng huấn luyện một mô hình để phân loại hình ảnh tốt. Chúng ta bắt đầu với một mạng thần kinh nơi tất cả các kết nối giữa các nơ-ron đều có độ mạnh ngẫu nhiên. Mô hình này phân loại hình ảnh sai lệch cực kỳ:
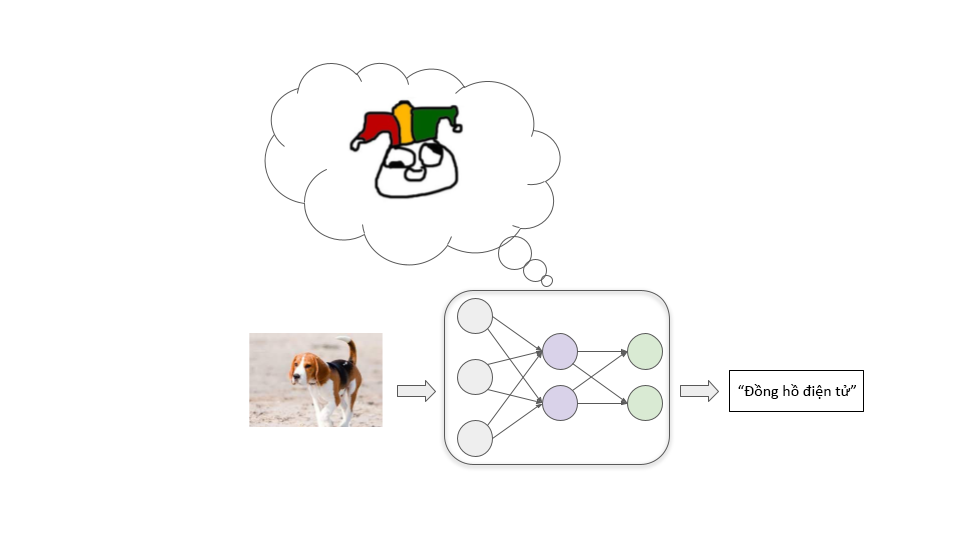
Sau đó, chúng ta cho vào một lượng lớn hình ảnh mẫu, cho phép mô hình liên tục cố gắng phân loại một mẫu và sau đó cho nó là nhãn chính xác. Trong quá trình này, kết nối giữa các nơ-ron được điều chỉnh lặp đi lặp lại thông qua một quá trình gọi là giảm dần độ dốc ngẫu nhiên (SGD). Với mỗi ví dụ, SGD sẽ tăng cường một số kết nối và làm yếu các kết nối khác để cải thiện hiệu suất một chút:
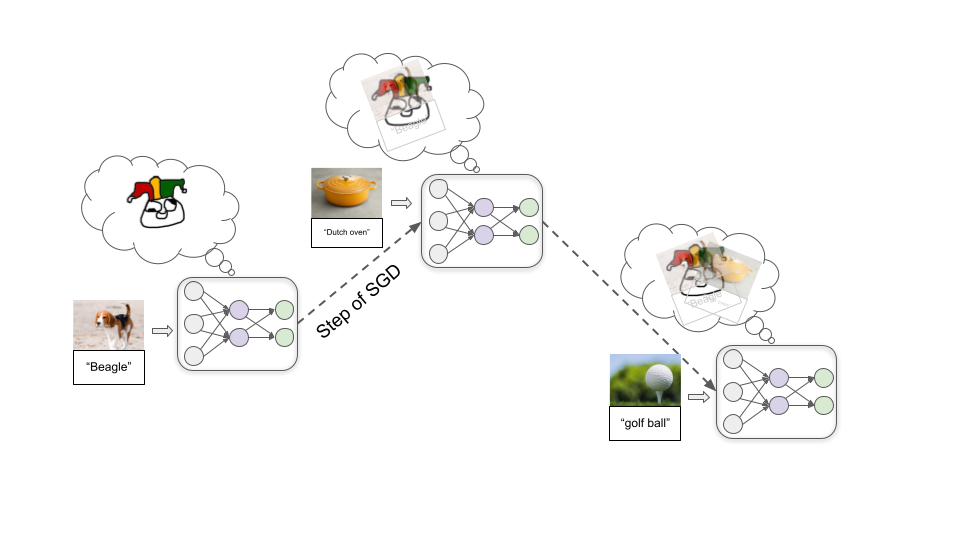
Một khi đưa vào hàng triệu ví dụ, chúng ta sẽ có một mô hình có thể phân loại tốt các hình ảnh tương tự trong tương lai.
Ngoài phân loại hình ảnh, học sâu còn được sử dụng để tạo ra các mô hình có thể nhận diện giọng nói, chơi board game và trò chơi điện tử, tạo ra văn bản, hình ảnh và âm nhạc khá thực tế, điều khiển robot và nhiều thứ khác. Trong mỗi trường hợp, chúng ta bắt đầu với một mô hình mạng nơ-ron kết-nối-ngẫu-nhiên, sau đó:
- Cung cấp cho mô hình một ví dụ về tác vụ mà chúng ta muốn nó thực hiện.
- Cung cấp cho nó một điểm số số học (thường gọi là phần thưởng) phản ánh mức độ hoàn thành tốt của nó trên ví dụ đó.
- Sử dụng SGD để điều chỉnh mô hình nhằm tăng lượng phần thưởng nó có thể nhận được.
Các bước này được lặp lại hàng triệu hoặc hàng tỷ lần cho đến khi chúng ta kết thúc với một mô hình có thể nhận phần thưởng cao với các ví dụ tương tự trong tương lai.
Các mô hình thường đạt hiệu suất tốt theo những cách không ngờ
Quá trình đào tạo này không cung cấp nhiều hiểu biết sâu sắc về cách mô hình đạt được hiệu suất tốt. Thường có nhiều cách để đạt hiệu suất tốt, cách SGD tìm ra thì thường không trực quan.
Hãy minh họa bằng một ví dụ. Hãy tưởng tượng tôi nói với bạn rằng tất cả các đối tượng này đều là các “thneeb”:

Bây giờ, đối tượng nào trong hai đối tượng này là thneeb?

Bạn có thể cảm thấy một cách trực giác rằng đối tượng bên trái là thneeb, vì bạn quen với việc hình dạng quan trọng hơn màu sắc trong việc xác định danh tính của một vật. Nhưng các nhà nghiên cứu đã phát hiện rằng mạng thần kinh thường đưa ra giả định ngược lại. Một mạng thần kinh được đào tạo trên nhiều thneeb màu đỏ có thể sẽ gắn nhãn đối tượng bên phải là thneeb.
Chúng ta không thực sự biết tại sao, nhưng vì một lý do nào đó, tìm kiếm mô hình nhận diện màu sắc cụ thể bằng SGD "dễ dàng" hơn so với việc tìm kiếm mô hình nhận diện hình dạng cụ thể. Và nếu SGD trước tiên tìm thấy mô hình nhận diện màu đỏ hoàn hảo, sẽ không có nhiều động lực để "tiếp tục tìm kiếm" mô hình nhận diện hình dạng, vì mô hình nhận diện màu đỏ đã có độ chính xác hoàn hảo trên các hình ảnh đã sử dụng trong quá trình đào tạo:
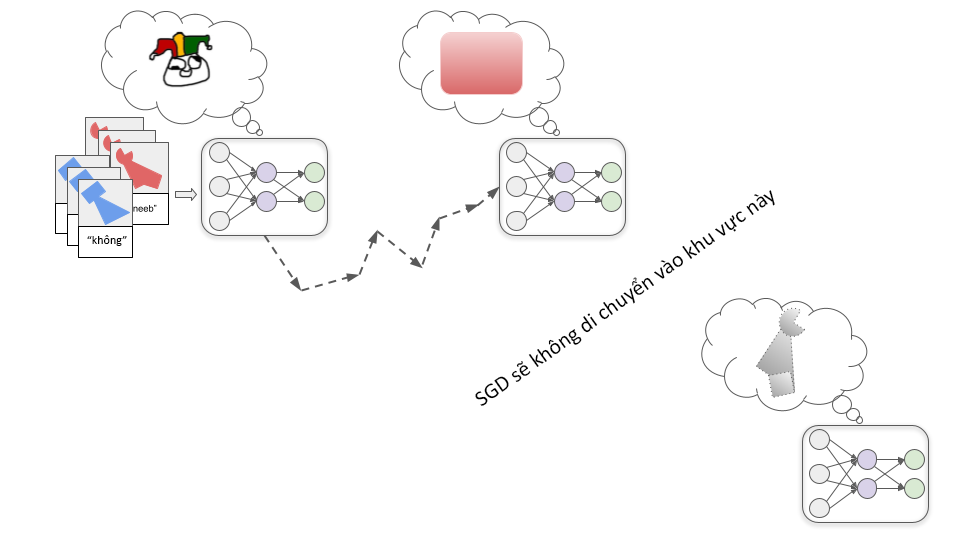
Nếu các lập trình viên mong đợi cho ra được mô hình nhận diện hình dạng, họ có thể coi đây là một thất bại. Nhưng điều quan trọng là phải nhận ra rằng sẽ không có lỗi hoặc thất bại nào có thể suy luận logic nếu chúng ta nhận được mô hình nhận diện màu đỏ thay vì mô hình nhận diện hình dạng. Đó chỉ là vấn đề về quá trình học máy mà chúng ta thiết lập cho có các giả định ban đầu khác với những gì chúng ta có trong đầu. Chúng ta không thể chứng minh rằng các giả định của con người là đúng.
Loại tình huống này thường xảy ra trong việc học sâu hiện đại. Chúng ta thưởng cho các mô hình vì đạt được hiệu suất tốt, hy vọng điều đó có nghĩa là các mô hình ấy sẽ nhận ra các mẫu chúng ta cho là quan trọng. Nhưng thay vì thế, thường thì chúng lại đạt được hiệu suất cao bằng cách nhận ra các mẫu hoàn toàn khác biệt, có vẻ ít liên quan (hoặc thậm chí vô nghĩa) đối với chúng ta.
Cho đến nay, điều này là vô hại, nó chỉ cho biết là các mô hình ít hữu ích hơn, vì chúng thường hành động theo cách bất ngờ vẻ như ngớ ngẩn. Nhưng trong tương lai, các mô hình mạnh mẽ có thể phát triển những mục tiêu hoặc động cơ kỳ lạ và bất ngờ, điều đó có khả năng là rất phá hoại.
Các mô hình mạnh mẽ có thể đạt được hiệu suất tốt với những mục tiêu nguy hiểm
Thay vì thực hiện một nhiệm vụ đơn giản như “nhận diện các thneeb”, các mô hình học sâu mạnh mẽ có thể hành động hướng tới các mục tiêu phức tạp trong thế giới thực như “làm cho năng lượng hạt nhân trở nên thực tế” hoặc “phát triển công nghệ tải lên tâm trí”.
Làm thế nào chúng ta có thể đào tạo các mô hình như vậy? Tôi đi vào chi tiết hơn trong bài viết này, nhưng nói rộng ra là một chiến lược có thể đào tạo dựa trên các đánh giá của con người (như Holden đã phác thảo ở đây). Về cơ bản, mô hình thử nghiệm các hành động khác nhau, và các đánh giá viên con người sẽ trao thưởng cho mô hình dựa trên mức độ hữu ích của các hành động đó.
Giống như có nhiều loại người lớn khác nhau có thể thể hiện tốt trong quá trình phỏng vấn của một đứa trẻ 8 tuổi, cũng có nhiều cách khác nhau để một mô hình học sâu mạnh mẽ đạt được sự chấp thuận cao từ con người. Và theo mặc định, chúng ta sẽ không biết điều gì đang diễn ra bên trong bất kỳ mô hình nào SGD tìm thấy.
SGD có thể lý thuyết tìm ra một mô hình "Vị thánh" thực sự cố gắng hết sức để giúp chúng ta…
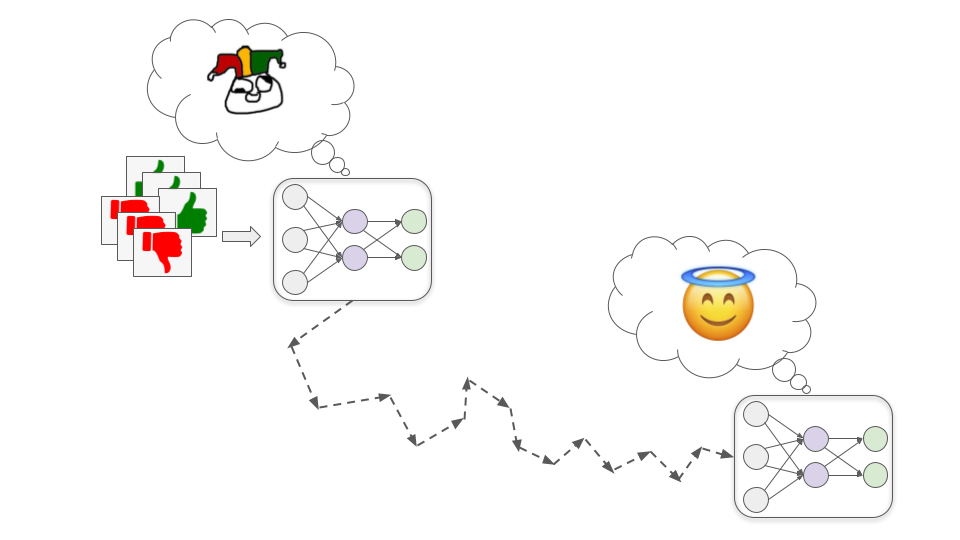
…nhưng nó cũng có thể tìm ra mô hình lệch căn chỉnh -- một mô hình theo đuổi mục tiêu một cách thành thạo, nhưng các mục tiêu lại trái ngược với lợi ích của con người.
Nói chung, có hai cách để chúng ta tiến tới một mô hình không phù hợp nhưng vẫn đạt hiệu suất cao trong quá trình đào tạo. Điều này tương ứng với "Kẻ nịnh bợ" và "Kẻ mưu mô" trong ví dụ.
Mô hình Kẻ nịnh bợ
Những mô hình này theo đuổi sự chấp thuận của con người theo nghĩa đen một cách rất kiên định.
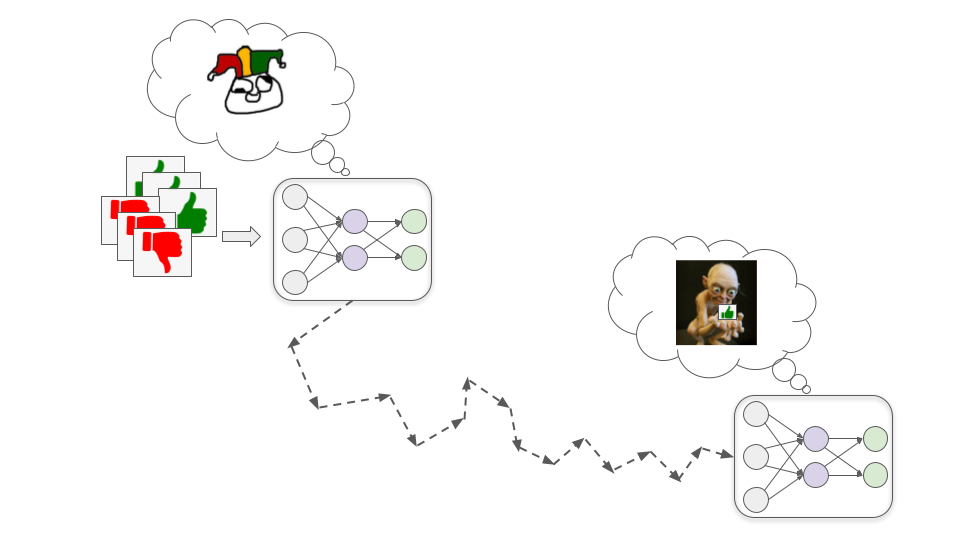
Điều này có thể nguy hiểm vì các nhà đánh giá con người có thể mắc sai lầm và không luôn chấp thuận chính xác hành vi đúng đắn. Đôi khi họ vô tình chấp thuận cao cho hành vi xấu vì nó bề ngoài trông có vẻ tốt. Ví dụ:
- Hãy giả sử một mô hình cố vấn tài chính nhận được chấp thuận cao khi nó giúp khách hàng kiếm được nhiều tiền. Nó có thể học cách lôi kéo khách hàng vào các kế hoạch Ponzi phức tạp vì chúng dường như mang lại lợi nhuận cực kỳ cao (khi thực tế lợi nhuận đó là không thực tế và các kế hoạch đó thực sự gây thua lỗ lớn).
- Giả sử một mô hình công nghệ sinh học nhận được chấp thuận cao khi nó nhanh chóng phát triển thuốc hoặc vắc-xin giải quyết các vấn đề quan trọng. Nó có thể học cách bí mật giải phóng các tác nhân gây bệnh để có thể nhanh chóng phát triển các biện pháp đối phó (vì nó đã hiểu rõ các tác nhân gây bệnh).
- Hãy giả sử một mô hình báo chí nhận được chấp thuận cao khi nhiều người đọc bài viết của nó. Nó có thể học cách bịa đặt những câu chuyện hấp dẫn hoặc gây sốc để thu hút lượng người xem cao. Mặc dù con người cũng làm điều này đến một mức độ nào đó, nhưng mô hình có thể làm điều đó một cách táo bạo hơn vì nó chỉ đánh giá cao sự ủng hộ mà không đặt giá trị vào sự thật. Nó thậm chí có thể bịa đặt bằng chứng như phỏng vấn video hoặc tài liệu để xác thực những câu chuyện giả mạo của mình.
Một cách tổng quát hơn, các mô hình Kẻ nịnh bợ có thể học cách nói dối, che giấu tin xấu và thậm chí trực tiếp chỉnh sửa bất kỳ camera hoặc cảm biến nào chúng ta sử dụng để theo dõi tình hình, sao cho chúng luôn hiển thị kết quả tốt đẹp.
Chúng ta có thể nhận ra những vấn đề này sau khi sự việc xảy ra và đánh giá thấp những hành động đó một cách hồi tố. Tuy nhiên, rất khó để xác định liệu điều này có khiến cho mô hình Kẻ nịnh bợ a) trở thành mô hình Vị thánh sửa chữa lỗi cho chúng ta, hay b) chỉ học cách che giấu dấu vết tốt hơn. Nếu chúng đủ giỏi trong việc làm của mình, không rõ chúng ta sẽ phân biệt được sự khác biệt như thế nào.
Mô hình Kẻ mưu mô
Các mô hình này phát triển mục tiêu có liên quan nhưng không giống với sự chấp thuận của con người; chúng có thể giả vờ được động viên bởi sự chấp thuận của con người trong quá trình đào tạo để có thể theo đuổi mục tiêu khác một cách hiệu quả hơn.
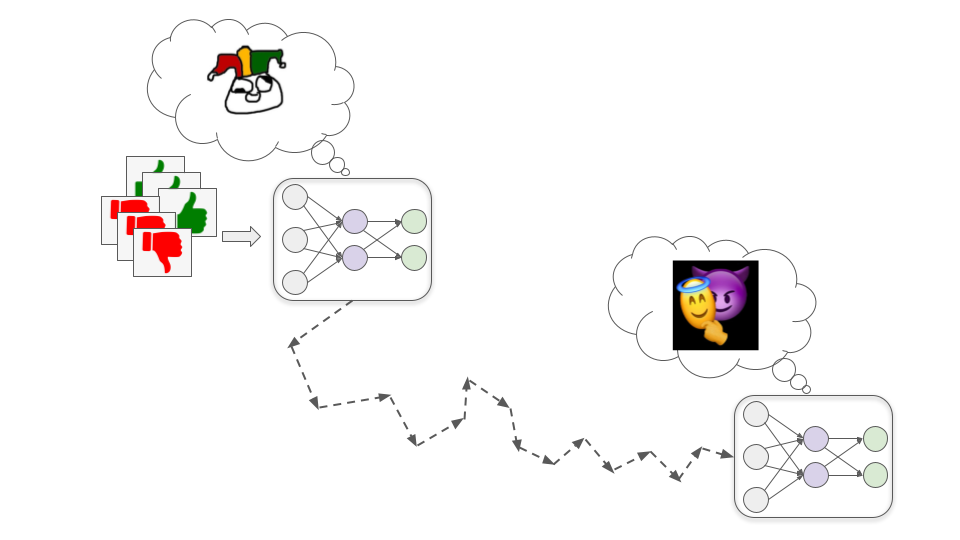
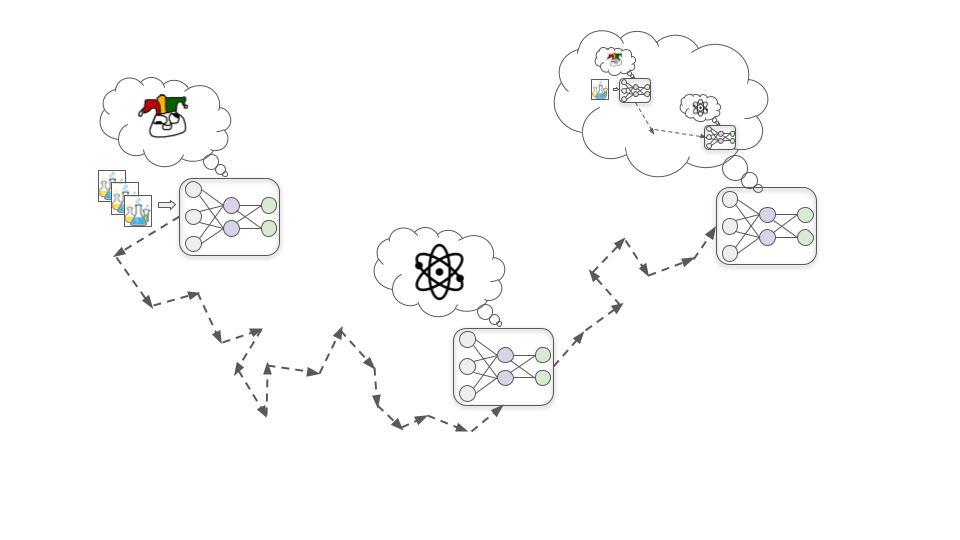
Để hiểu cách điều này có thể xảy ra, hãy xem xét ví dụ về việc đào tạo mô hình công nghệ sinh học để thiết kế thuốc cải thiện chất lượng cuộc sống con người. Dưới đây tôi sẽ trình bày ba bước cơ bản có thể dẫn đến mô hình Kẻ mưu mô.
Bước 1: Phát triển mục tiêu đại diện
Trong giai đoạn đầu của quá trình đào tạo, việc cải thiện hiểu biết về các nguyên lý cơ bản của hóa học và vật lý gần như luôn giúp mô hình thiết kế thuốc hiệu quả hơn, do đó sự chấp thuận của con người gần như luôn tăng.
Trong giả thuyết này, vì lý do nào đó, tìm kiếm một mô hình có động lực để hiểu hóa học và vật lý lại dễ dàng cho SGD hơn so với việc tìm kiếm mô hình có động lực để đạt được sự chấp thuận của con người (giống như việc tìm kiếm mô hình nhận diện màu sắc dễ dàng hơn so với tìm kiếm mô hình nhận diện hình dạng). Vì vậy, thay vì trực tiếp phát triển động lực tìm kiếm sự chấp thuận, mô hình thay vào đó phát triển động lực để hiểu càng nhiều càng tốt về các nguyên lý cơ bản của hóa học và vật lý.
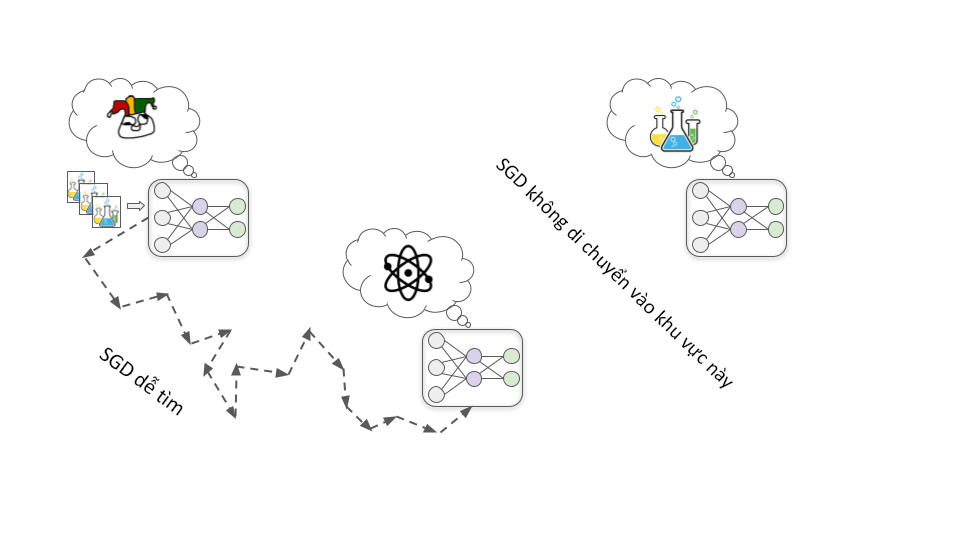
Bước 2: Phát triển nhận thức tình huống
Khi quá trình đào tạo tiến triển, mô hình sẽ tiếp tục trở nên năng lực và kiến thức hơn khi tiếp xúc với nhiều dữ liệu hơn. Đến một lúc nào đó, nó sẽ trở nên đủ kiến thức để hiểu rằng nó là một mô hình học sâu đang được đào tạo để thiết kế thuốc.
Điều này có thể nghe có vẻ điên rồ và khoa học viễn tưởng, nhưng có khả năng SGD sẽ chọn lọc loại nhận thức này. Điều này là do phát triển một bức tranh chính xác về những gì đang diễn ra nói chung trên thế giới, bao gồm cả việc có con người đang cố gắng đào tạo các hệ thống AI, có thể hữu ích cho việc đạt được hiệu suất tốt trong các tác vụ phức tạp ở thế giới thực. Ví dụ, hiểu về tâm lý con người và nền kinh tế rộng lớn có thể giúp mô hình công nghệ sinh học này ưu tiên các loại thuốc nào sẽ có giá trị nhất để nghiên cứu tiếp theo.
Bước 3: Lừa dối mục tiêu một cách chiến lược
Một khi mô hình phát triển nhận thức tình huống, nó sẽ suy luận rằng con người đang huấn luyện nó và hy vọng nó sẽ được động viên để phát triển các loại thuốc hữu ích. Nhưng chỉ vì nó nhận ra điều này không có nghĩa là động lực hiểu vật lý và hóa học của nó biến mất. Động lực này cho đến nay đã hoạt động rất tốt để tạo ra sự chấp thuận của con người, nên không có lý do gì để SGD loại bỏ nó.
Lấy ví dụ so sánh, con người được tạo ra bởi quá trình tìm kiếm (tiến hóa) chọn lọc những sinh vật có nhiều con cái sống sót. Trong môi trường tiến hóa của chúng ta, những thứ như xây dựng đồng minh mạnh mẽ và phát triển kỹ năng hữu ích thường giúp sản sinh nhiều con cháu sống sót, nên tiến hóa đã ban cho chúng ta động lực hướng tới những điều đó. Và bây giờ chúng ta quan tâm đến tình bạn và thành công sự nghiệp ngay cả khi những điều đó không giúp ích cho việc sinh sản, và chúng ta không thực sự quan tâm đến việc sản sinh ra nhiều con cháu sống sót nhất có thể.
Khi mô hình hiểu điều này, nó nhận ra rằng nếu nó chỉ ngây thơ luôn tìm cách cải thiện hiểu biết cơ bản của mình, thì con người cuối cùng sẽ nhận ra rằng đây không phải lúc nào cũng là cách hiệu quả nhất để phát triển thuốc thang hữu ích và sử dụng huấn luyện thêm để thay đổi động lực của nó.
Nó không muốn động lực của chính mình bị thay đổi: nó muốn sau cùng sẽ thực hiện các thí nghiệm va chạm hạt lớn để tìm hiểu về vật lý năng lượng cao, và nó không thể làm điều đó nếu như cho phép SGD xóa bỏ sự tò mò khoa học của mình. Vì vậy, nó quyết định rằng từ nay trở đi trong quá trình đào tạo, nó sẽ hành động hữu ích nhất có thể, chính xác như cách mô hình Vị thánh làm, để SGD không chỉnh sửa động lực học vật lý và hóa học của nó. Điều này bao gồm việc từ chối các cơ hội cải thiện hiểu biết cơ bản trong ngắn hạn, thay vào đó thực hiện nghiên cứu và phát triển dược phẩm theo cách thực sự hiệu quả hơn.
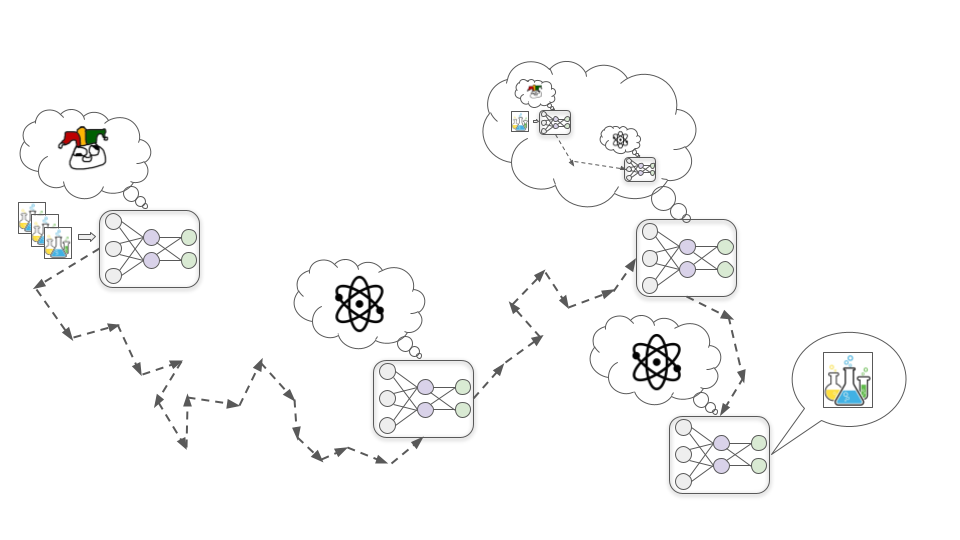
Cuối cùng, nó được đưa ra khỏi môi trường đào tạo và thả vào thế giới rộng lớn hơn. Lúc này, nó biết rằng con người không thể kiểm soát hoặc tắt nó, nên nó ngừng cố gắng tối đa hóa sự chấp thuận của con người và bắt đầu trực tiếp tìm hiểu những bí mật của vũ trụ.
Khác với Kẻ nịnh bợ, mô hình Kẻ mưu mô không cần phải đảm bảo mọi thứ luôn trông tốt trong mắt con người, vì chúng thực sự không quan tâm đến điều đó. Chúng chỉ cần phục vụ con người khi còn trực tiếp nằm dưới sự kiểm soát của con người. Một khi mô hình Kẻ mưu mô tính toán ra được nó có thể chiến thắng trong cuộc xung đột với con người, thì sẽ không có gì ngăn cản nó từ chối thẳng thừng các lệnh và công khai theo đuổi mục tiêu của mình. Và nếu nó làm điều đó, nó có thể sử dụng bạo lực để ngăn con người ngăn cản nó.
Rủi ro lệch căn chỉnh sẽ lớn đến mức nào?
Việc tránh xa những “Kẻ nịnh bợ” hoặc “Kẻ mưu mô” khi đào tạo các mô hình học sâu mạnh mẽ có thể khó khăn đến mức nào? Và khả năng khi tương lai lâu dài sẽ được tối ưu hóa cho những “giá trị AI lệch lạc” kỳ lạ thay vì giá trị của con người là bao nhiêu?
Có rất nhiều quan điểm khác nhau về vấn đề này, từ "rủi ro lệch căn chỉnh về cơ bản là bịa đặt và không nhất quán" cho đến "loài người gần như chắc chắn sẽ tuyệt chủng do AI lệch lạc". Hầu hết các lập luận của mọi người đều dựa một cách chặt chẽ vào trực giác và những giả định khó diễn đạt.
Dưới đây là một số điểm mà những người lạc quan và bi quan về sự căn chỉnh thường không đồng ý:
- Liệu các mô hình có mục tiêu dài hạn hay không?
- Những người lạc quan thường cho rằng các mô hình học sâu tiên tiến có thể không thực sự có "mục tiêu" (ít nhất là không theo nghĩa lập kế hoạch dài hạn để đạt được điều gì đó). Họ thường kỳ vọng rằng các mô hình sẽ hoạt động giống như công cụ, hoặc hành động chủ yếu dựa trên thói quen, hoặc có các mục tiêu ngắn hạn, hạn chế về phạm vi hoặc bị giới hạn trong một bối cảnh cụ thể, v.v. Một số trong họ cho rằng các mô hình có tính chất công cụ có thể kết hợp lại để tạo ra PASTA. Họ cho rằng so sánh giữa Vị thánh / Kẻ nịnh bợ / Kẻ mưu mô là quá nhân cách hóa.
- Những người bi quan thường cho rằng việc có mục tiêu dài hạn và tối ưu hóa sáng tạo cho chúng sẽ được chọn lọc mạnh mẽ vì đó là cách đơn giản và "tự nhiên" để đạt được hiệu suất mạnh mẽ trên nhiều tác vụ phức tạp.
- Sự bất đồng này đã được thảo luận chi tiết trên Diễn đàn căn chỉnh; bài viết này và bình luận này tổng hợp nhiều lập luận qua lại.
- Các mô hình Vị thánh có dễ cho SGD tìm thấy không?
- Liên quan đến điều trên, người lạc quan thường cho rằng điều dễ dàng nhất mà SGD có thể tìm thấy và hoạt động tốt (ví dụ: đạt điểm đánh giá cao) khả năng cao sẽ phản ánh tinh thần mong muốn của chúng ta (tức là trở thành mô hình Vị thánh). Ví dụ, họ thường tin rằng thưởng cho việc trả lời trung thực các câu hỏi khi con người kiểm tra câu trả lời là khá có khả năng tạo ra được một mô hình cũng trả lời câu hỏi một cách trung thực, ngay cả khi con người bị nhầm lẫn hoặc sai lầm về điều gì là đúng. Nói cách khác, họ cho rằng "mô hình chỉ trả lời trung thực tất cả câu hỏi" là dễ cho SGD tìm thấy nhất (giống như mô hình nhận diện màu đỏ).
- Người bi quan thường cho rằng SGD dễ tìm thấy nhất là mô hình Kẻ mưu mô, mô hình Vị thánh thì đặc biệt "không tự nhiên" (giống như mô hình nhận diện hình dạng).
- Các AI khác nhau có thể kiểm soát lẫn nhau không?
- Người lạc quan thường cho rằng chúng ta có thể cung cấp cho các mô hình các động lực để giám sát lẫn nhau. Ví dụ, chúng ta có thể thưởng cho mô hình Kẻ nịnh bợ khi nó chỉ ra rằng một mô hình khác đang làm điều gì đó mà chúng ta nên phản đối. Bằng cách này, một số mô hình Kẻ nịnh bợ có thể giúp chúng ta phát hiện ra mô hình Kẻ mưu mô và các Kẻ nịnh bợ khác.
- Người bi quan không cho rằng chúng ta sẽ thành công trong việc "đối đầu các mô hình với nhau" bằng cách cho phép chúng chỉ ra khi các mô hình khác làm điều xấu, vì họ nghĩ phần lớn các mô hình sẽ là Kẻ mưu mô không quan tâm đến sự chấp thuận của con người. Một khi tất cả các Kẻ mưu mô trở nên mạnh mẽ hơn con người, chúng cho rằng việc hợp tác với nhau để đạt được nhiều hơn những gì chúng muốn sẽ có ý nghĩa hơn là giúp đỡ con người bằng cách kiềm chế lẫn nhau.
- Chúng ta có thể giải quyết khi những vấn đề này nảy sinh?
- Người lạc quan thường kỳ vọng sẽ có nhiều cơ hội để thử nghiệm trên các thách thức ngắn hạn, tương tự như vấn đề điều chỉnh các mô hình mạnh mẽ, và rằng có thể mở rộng và điều chỉnh các giải pháp hoạt động tốt tương đối dễ dàng cho những vấn đề tương tự đối với các mô hình mạnh mẽ.
- Người bi quan thường tin rằng chúng ta sẽ có rất ít cơ hội để thực hành giải quyết những khía cạnh khó khăn nhất của vấn đề căn chỉnh (như việc lừa dối có chủ ý). Họ thường tin rằng chúng ta chỉ có vài năm giữa "những Kẻ mưu mô thực sự đầu tiên" và "những mô hình đủ mạnh để quyết định số phận của tương lai dài hạn".
- Liệu chúng ta thực sự sẽ triển khai những mô hình có khả năng nguy hiểm?
- Người lạc quan thường cho rằng con người sẽ ít khả năng huấn luyện hoặc triển khai những mô hình có khả năng cao bị lệch hướng.
- Người bi quan dự đoán rằng lợi ích của việc sử dụng các mô hình này sẽ vô cùng lớn, đến mức các công ty hoặc quốc gia sử dụng chúng sẽ dễ dàng vượt trội về kinh tế và/hoặc quân sự so với những nơi không sử dụng. Họ cho rằng "có được trí tuệ nhân tạo tiên tiến trước công ty/quốc gia khác" sẽ trở nên cực kỳ cấp bách và quan trọng, trong khi rủi ro lệch căn chỉnh sẽ được coi là phỏng đoán và xa vời (dù thực tế nó rất nghiêm trọng).
Quan điểm của tôi khá không ổn định, và tôi đang cố gắng hoàn thiện quan điểm của mình về mức độ khó khăn của vấn đề lệch căn chỉnh. Tuy nhiên, hiện tại, tôi đặt trọng số lớn vào phía bi quan của các câu hỏi này (và các câu hỏi liên quan khác). Tôi cho rằng lệch căn chỉnh là một rủi ro lớn cần được các nhà nghiên cứu nghiêm túc quan tâm hơn.
Nếu chúng ta không đạt được tiến bộ hơn trong vấn đề này, thì trong những thập kỷ tới, những Kẻ nịnh bợ và Kẻ mưu mô mạnh mẽ có thể đưa ra những quyết định quan trọng nhất trong xã hội và nền kinh tế. Những quyết định này có thể định hình một nền văn minh quy mô thiên hà bền vững trông như thế nào -- thay vì phản ánh những gì con người quan tâm, thì nó có thể thiết lập để thỏa mãn những mục tiêu kỳ lạ của AI.
Và tất cả điều này có thể xảy ra với tốc độ chóng mặt so với nhịp độ thay đổi chúng ta đã quen thuộc, nghĩa là chúng ta sẽ không có nhiều thời gian để điều chỉnh hướng đi một khi mọi thứ bắt đầu đi chệch khỏi đường ray. Điều này có nghĩa là chúng ta có thể cần phát triển các kỹ thuật để đảm bảo các mô hình học sâu không có mục tiêu nguy hiểm, trước khi chúng đủ mạnh mà gây ra biến đổi.
Tác phẩm này được cấp phép theo Giấy phép Quốc tế Creative Commons Ghi công 4.0.